
在大型语言模型(LLM)的浪潮下,多模态AI取得了飞速发展,尤其是在视觉语言(LVLM)领域,已经形成了成熟的研究范式。然而,与之形成鲜明对比的是,大型语音语言模型(LSLM)的发展却显得零散且步调缓慢。
该领域长期被碎片化的架构、不透明的训练数据和缺失的评估标准所困扰,导致研究之间难以进行公平比较,严重阻碍了技术的可复现性和社区的系统性进步。许多研究虽然发布了模型权重,但其赖以成功的关键——训练数据和配置细节——却常常被“雪藏”起来。
为了打破这一僵局,北京深度逻辑智能科技有限公司推出了LLaSO——首个完全开放、端到端的语音语言模型研究框架。

LLaSO旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是“全家桶”式的,包含了一整套开源的数据、基准和模型,希望以此加速LSLM领域的社区驱动式创新。

论文地址:https://arxiv.org/abs/2508.15418v1
代码地址:https://github.com/EIT-NLP/LLaSO
模型地址:https://huggingface.co/papers/2508.15418
LSLM领域的技术挑战与研究痛点
相比视觉语言模型(LVLM)领域已形成CLIP编码器+LLaVA范式的成熟生态,LSLM研究面临四大核心挑战:
1. 架构路径分化严重
当前LSLM架构主要包括外部特征融合、跨模态注意力机制、隐式对齐等多种技术方案,缺乏如LVLM领域般的统一范式。不同研究团队采用差异化架构,导致技术进展难以积累和比较。
2. 训练数据严重私有化
主流LSLM如Qwen-Audio、Kimi-Audio等均依赖私有数据训练,数据规模、质量、构成等关键信息不透明。这使得:
- 可复现性差:其他研究者无法复现相同结果
- 性能归因模糊:难以判断性能提升源于架构创新还是数据优势
- 研究门槛高:新入场者需要大量资源构建私有数据集
3. 任务覆盖局限性明显
现有数据集主要聚焦语义理解任务,对语音中的副语言学信息(paralinguistic information)如情感、口音、韵律、说话人特征等覆盖不足,限制了模型的全面语音理解能力。
4. 交互模态单一化
大多数LSLM仅支持”文本指令+音频输入”的单一交互模式,缺乏对”音频指令+文本输入”和纯音频交互等复杂模态组合的系统性支持。
LLaSO框架:三大核心组件构建完整生态
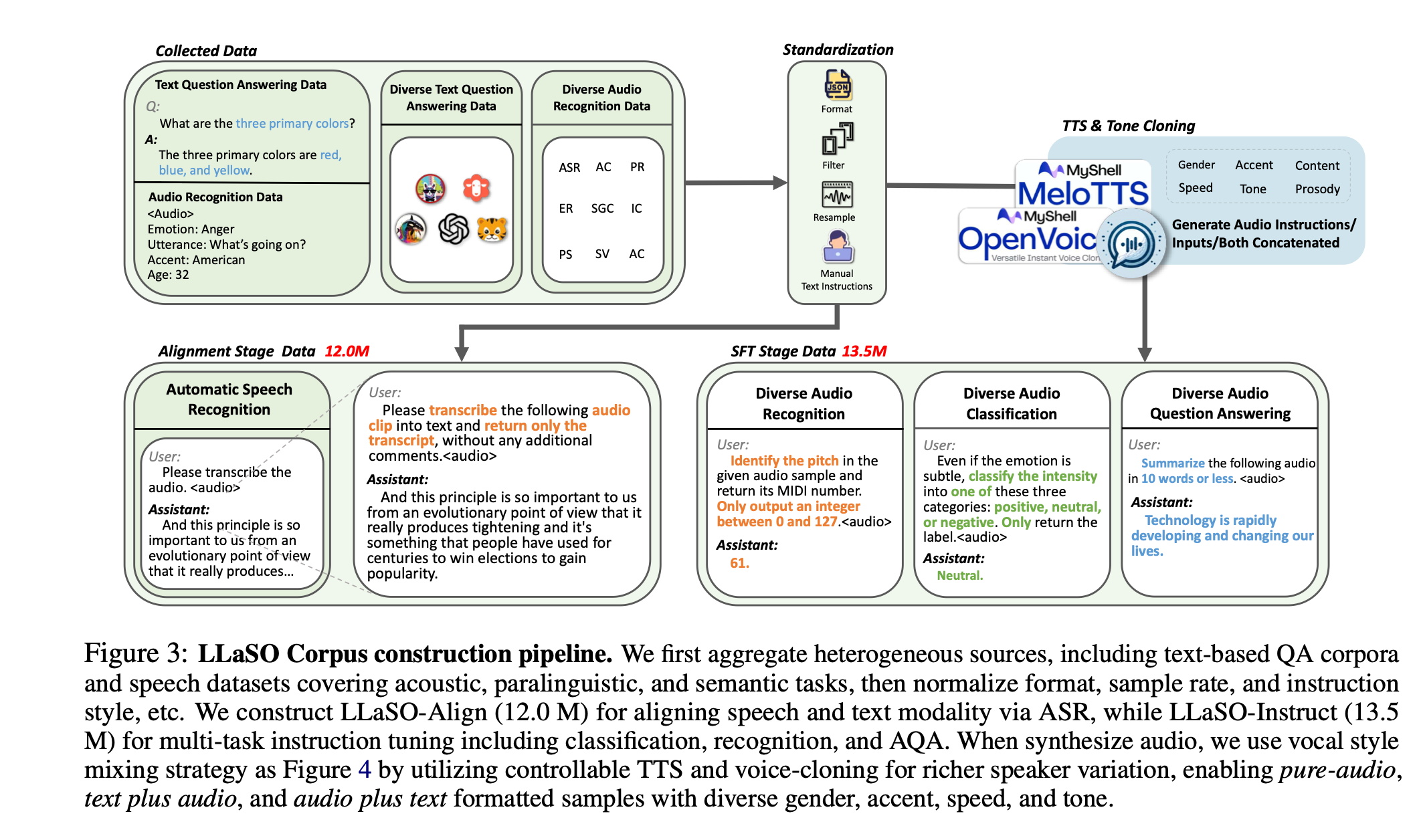
图一:llaso语料库的制作流程
LLaSO框架通过三个核心开源组件解决上述挑战:
LLaSO-Align:大规模语音-文本对齐数据集
- 数据规模:1200万语音-文本对齐样本
- 数据来源:聚合对话、有声书、多口音语音等多样化来源
- 技术目标:通过自动语音识别(ASR)任务建立语音表示与文本语义空间的精确对齐
- 质量控制:采用多重过滤机制确保数据质量和说话人多样性
LLaSO-Instruct:多任务指令微调数据集
- 数据规模:1350万多任务指令样本
- 任务覆盖:涵盖语言学、语义学、副语言学三大类共20项任务
- 语言学任务:ASR、翻译、总结等基础语言理解
- 语义学任务:问答、推理、内容分析等高级认知
- 副语言学任务:情感识别、口音检测、说话人分析等
- 模态支持:系统性支持三种交互配置
- 文本指令 + 音频输入(Text-Audio)
- 音频指令 + 文本输入(Audio-Text)
- 纯音频指令与输入(Audio-Audio)
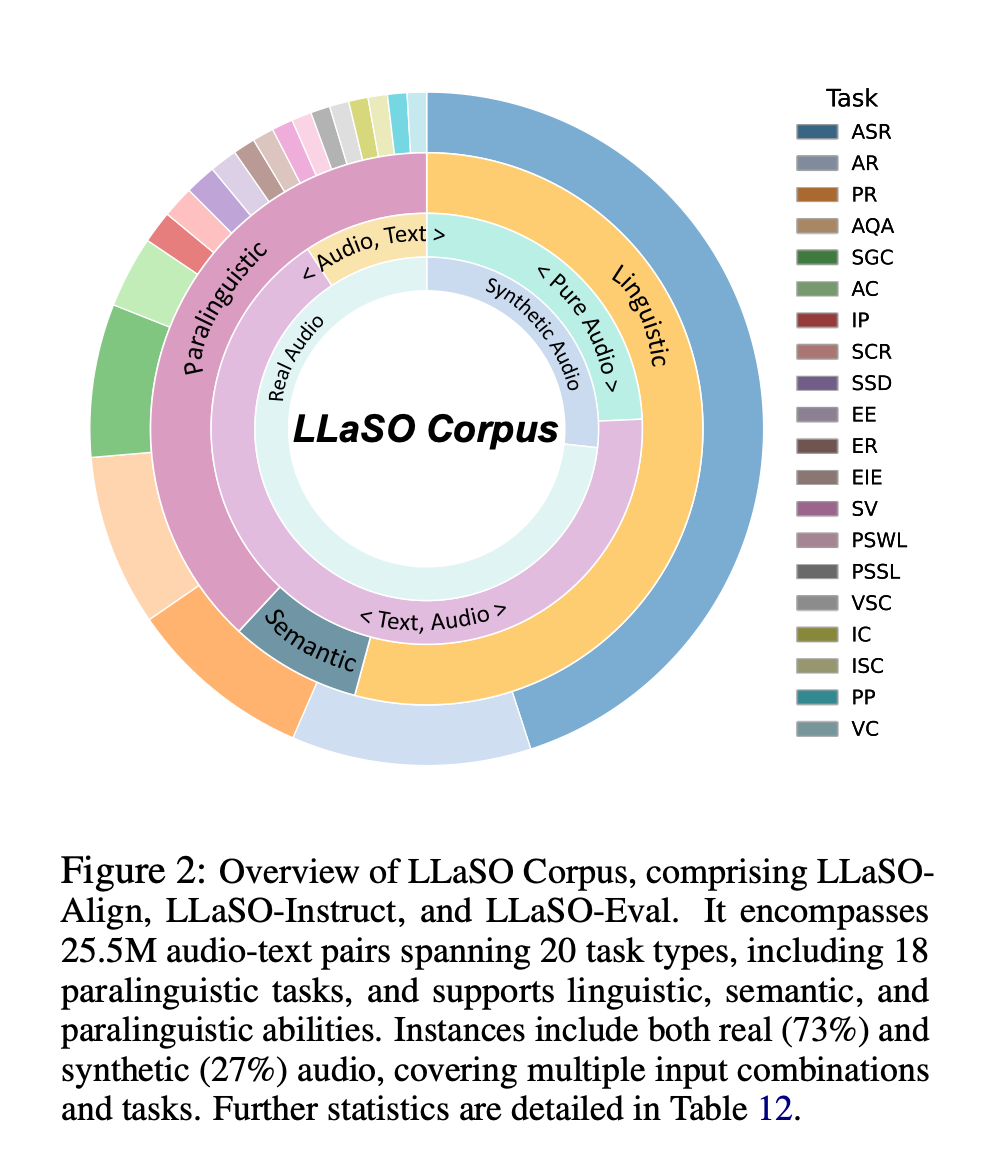
图二:LLaSO语料库的任务组成
LLaSO-Eval:标准化评估基准
- 样本规模:15,044个测试样本
- 数据隔离:与训练集严格分离,确保评估公平性
- 评估维度:覆盖所有20项任务的comprehensive evaluation
- 可复现性:提供统一评估协议和自动化评估工具
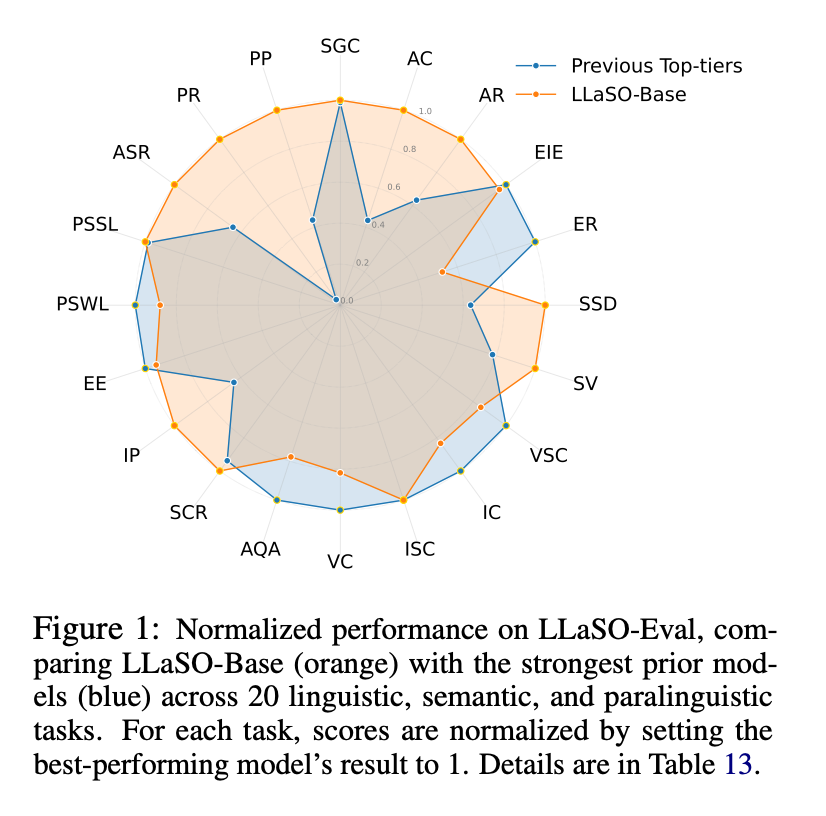
图三:LLaSO-Base在LLaSO-Eval基准测试上的表现结果
这三大组件共同构成了一个完整的训练、微调和评估流水线,为LSLM研究提供了前所未有的开放性和便利性。
LLaSO-Base:技术验证与性能基准
为验证框架有效性,逻辑智能团队基于LLaSO数据训练了38亿参数的参考模型LLaSO-Base。
模型架构设计
采用经典三阶段架构:
- 语音编码器:Whisper-large-v3,负责语音特征提取
- 模态投影器:多层感知机(MLP),实现语音-文本特征空间映射
- 语言模型backbone:Llama-3.2-3B-Instruct,提供语言理解和生成能力
两阶段训练策略
- 对齐阶段:冻结编码器和LLM,仅训练投影器,使用LLaSO-Align数据建立modality alignment
- 指令微调阶段:联合训练投影器和LLM,使用LLaSO-Instruct数据学习complex instruction following
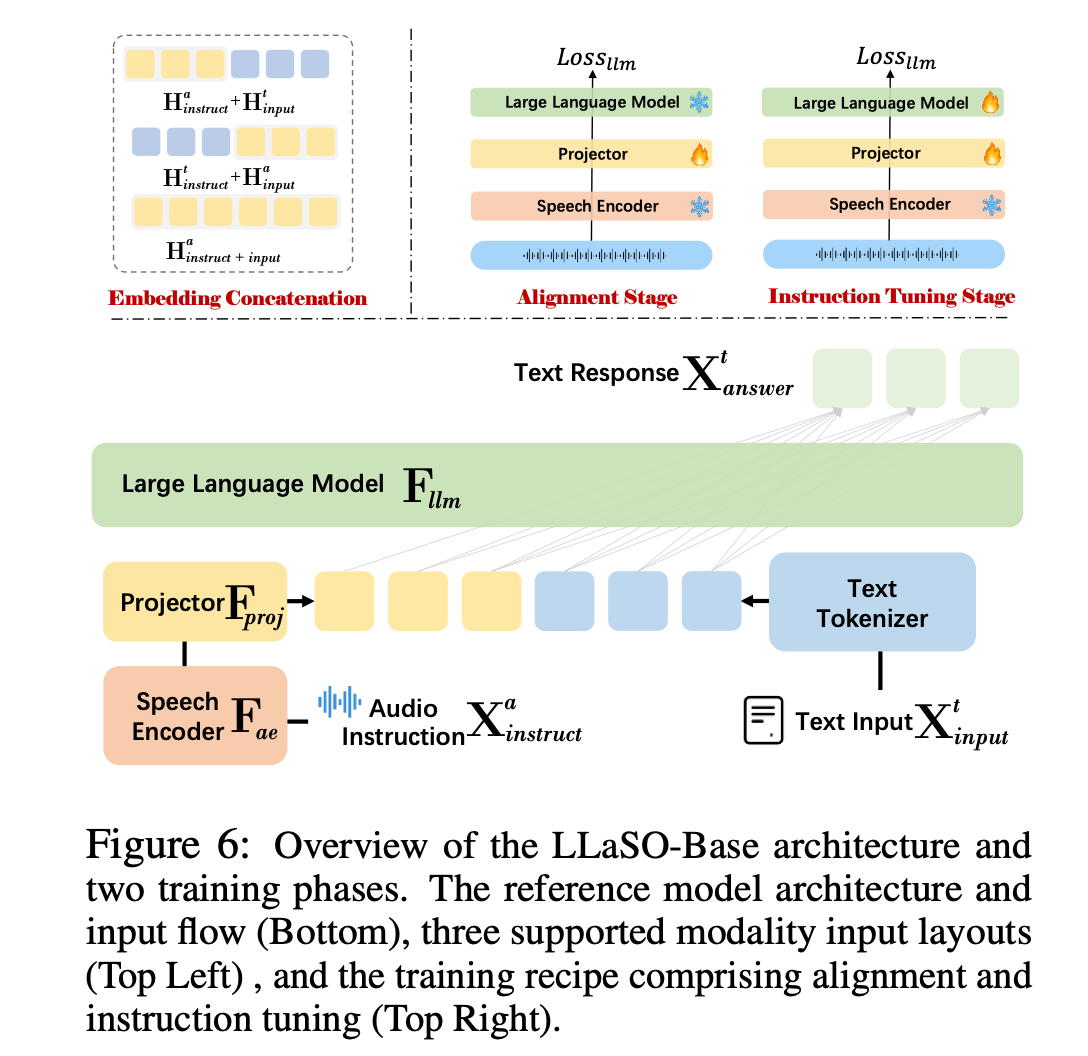
图四:LLaSO模型架构示意图
实验结果:性能验证与关键发现
整体性能表现
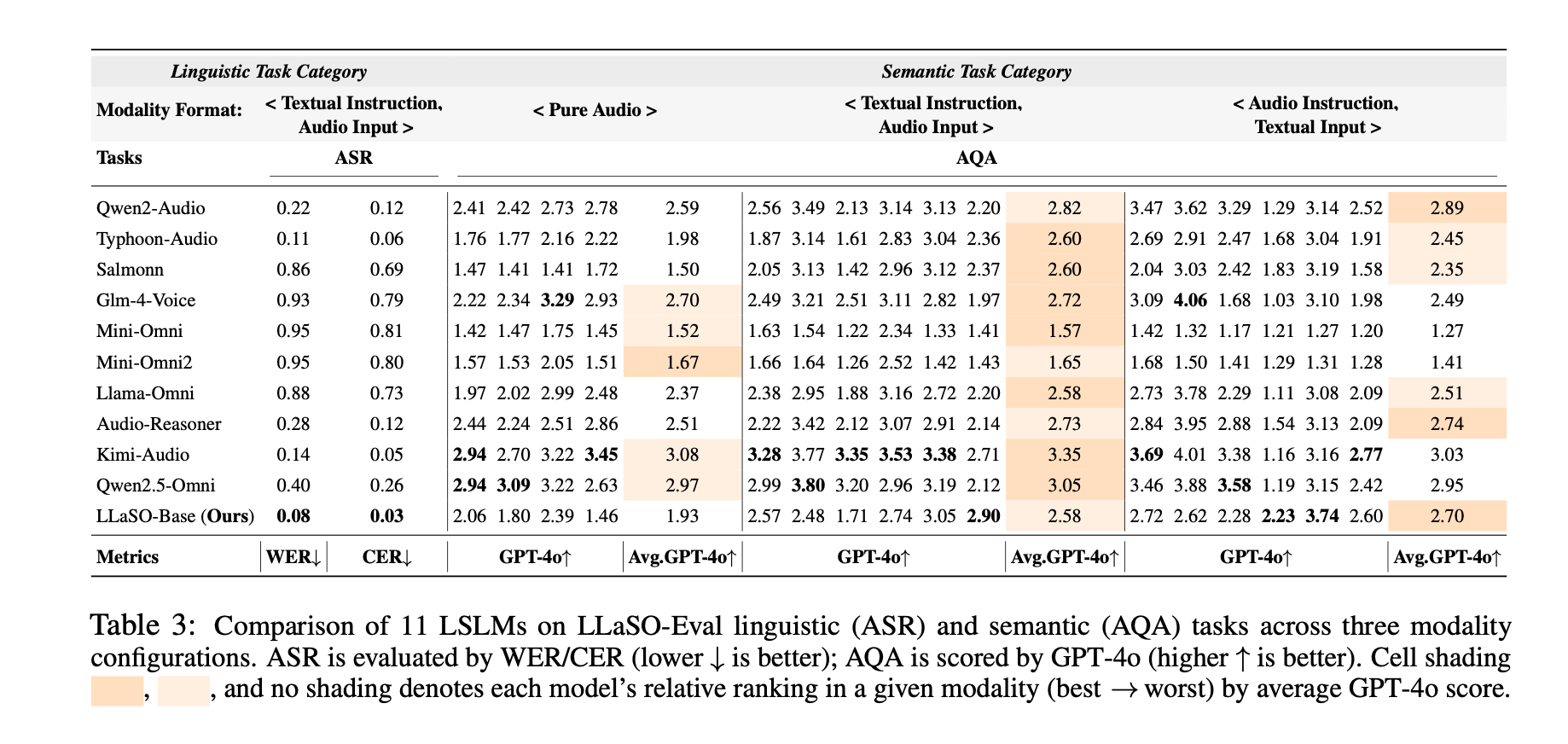
在LLaSO-Eval基准上,LLaSO-Base取得显著领先性能:
- LLaSO-Base: 0.72(综合归一化得分)
- Kimi-Audio: 0.65
- Qwen2-Audio: 0.57
- 其他8个对比模型均低于0.55
通过对11个主流LSLM的系统性评估,研究得出四个重要发现:
1. 任务多样性驱动整体性能
数据支撑:训练任务覆盖度与模型综合性能呈强正相关
- 高任务多样性模型(15+任务)平均得分0.65+
- 低任务多样性模型(<10任务)平均得分0.50-
- 任务多样性还显著降低模型拒答率(refusal rate)
2. 跨模态泛化能力有限
性能分析:
- Text-Audio模态:平均性能0.68(最成熟)
- Audio-Text模态:平均性能0.52(中等挑战)
- Audio-Audio模态:平均性能0.45(最大挑战)
模型在处理训练中未见过的模态组合时性能显著下降,表明当前LSLM的cross-modal generalization能力仍需提升。
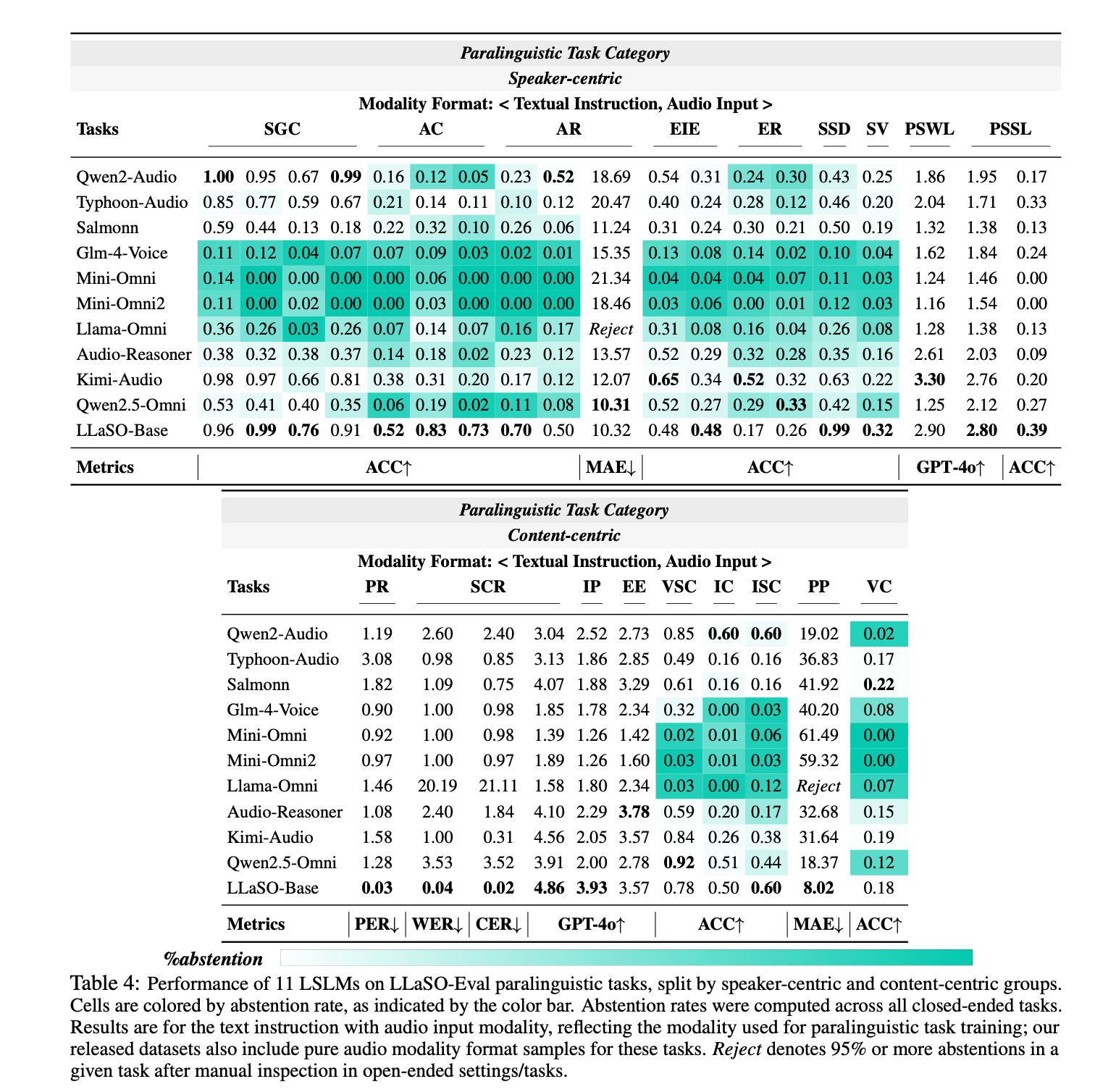
3. 纯音频交互是技术难点
Audio-Audio交互场景的性能普遍低于Audio-Text场景,这反映了:
- 音频指令理解的复杂性
- 音频-音频attention机制的不成熟
- 缺乏大规模Audio-Audio训练数据
4. 内容理解优于说话人分析
任务性能对比:
- 内容相关任务(意图识别、实体提取):平均准确率75%+
- 说话人相关任务(年龄、性别、口音识别):平均准确率60%-
这表明当前LSLM在semantic understanding方面已相对成熟,但在speaker characterization方面仍有较大提升空间。
图五:LLaSO-Base的实验结果
开源策略的技术价值与社区影响
对学术研究的推动作用
- 可复现性保障:完整开放的训练数据和代码实现
- 公平比较基础:统一评估基准消除evaluation bias
- 研究门槛降低:研究者可专注于算法创新而非数据收集
- 技术积累加速:基于统一框架的增量改进更易实现
对工业应用的促进效应
- 开发成本降低:相比私有数据方案节省数千万数据构建成本
- 技术风险可控:开源方案的透明性降低技术选型风险
- 定制化便利:开放架构支持针对性的领域adaptation
- 生态建设基础:为LSLM生态标准化提供参考实现
技术局限与未来方向
当前局限性
- 模型规模:38亿参数相比GPT-4级别模型仍有性能gap
- 多语言支持:主要针对英文和中文,其他语言覆盖有限
- 实时性能:大模型推理延迟对实时应用仍有挑战
- 长音频处理:对超长音频序列的处理效率有待优化
发展方向
- 模型scaling:探索更大规模模型的性能上限
- 效率优化:模型压缩、量化等技术降低部署门槛
- 多模态扩展:集成视觉信息实现Audio-Visual-Language understanding
- 领域适应:针对医疗、教育、客服等垂直领域的专用优化
结论
LLaSO作为首个完全开源的LSLM研究框架,通过提供大规模数据、统一基准和参考实现,为语音语言模型研究建立了透明、可复现的技术基础设施。其开源策略不仅降低了研究门槛,更重要的是为LSLM领域建立了统一的技术标准,有望推动该领域从”各自为战”向”协同创新”转变。
随着框架的广泛采用和社区贡献,LLaSO有望成为LSLM研究的”ImageNet时刻”,为构建真正理解人类语音nuance的AI系统奠定坚实基础。

